Algorithm Analysis In The Age of Embeddings

[ad_1]
On August 1st, 2018 an algorithm update took 50% of traffic from a client site in the automotive vertical. An analysis of the update made me certain that the best course of action was … to do nothing. So what happened?
Sure enough, on October 5th, that site regained all of its traffic. Here’s why I was sure doing nothing was the right thing to do and why I dismissed any E-A-T chatter.
E-A-T My Shorts

I find the obsession with the Google Rating Guidelines to be unhealthy for the SEO community. If you’re unfamiliar with this acronym it stands for Expertise, Authoritativeness and Trustworthiness. It’s central to the published Google Rating Guidelines.
The problem is those guidelines and E-A-T are not algorithm signals. Don’t believe me? Believe Ben Gomes, long-time search quality engineer and new head of search at Google.
“You can view the rater guidelines as where we want the search algorithm to go,” Ben Gomes, Google’s vice president of search, assistant and news, told CNBC. “They don’t tell you how the algorithm is ranking results, but they fundamentally show what the algorithm should do.”
So I am triggered when I hear someone say they “turned up the weight of expertise” in a recent algorithm update. Even if the premise were true, you have to connect that to how the algorithm would reflect that change. How would Google make changes algorithmically to reflect higher expertise?
Google doesn’t have three big knobs in a dark office protected by biometric scanners that allows them to change E-A-T at will.
Tracking Google Ratings
Before I move on I’ll do a deeper dive into quality ratings. I poked around to see if there are material patterns to Google ratings and algorithmic changes. It’s pretty easy to look at referring traffic from the sites that perform ratings.
![]()
The four sites I’ve identified are raterlabs.com, raterhub.com, leapforceathome.com and appen.com. At present there’s really only variants of appen.com, which rebranded in the last few months. Either way, create an advanced segment and you can start to see when raters have visited your site.
And yes, these are ratings. A quick look at the referral path makes it clear.
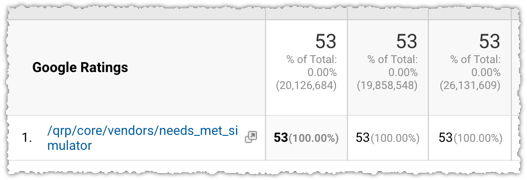
The /qrp/ stands for quality rating program and the needs_met_simulator seems pretty self-explanatory.
It can be interesting to then look at the downstream traffic for these domains.
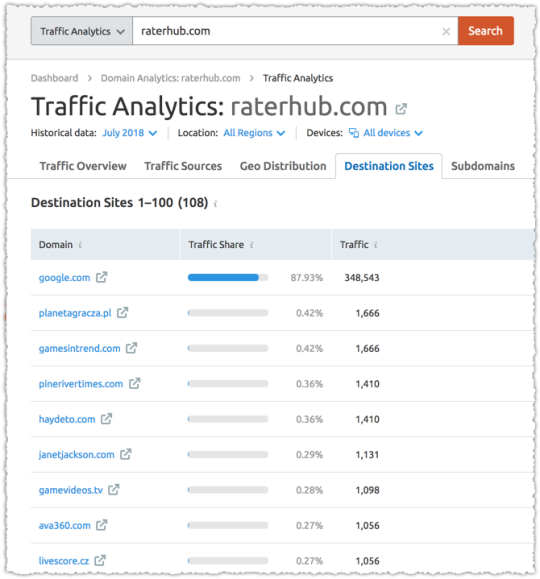
Go the extra distance and you can determine what page(s) the raters are accessing on your site. Oddly, they generally seem to focus on one or two pages, using them as a representative for quality.
Beyond that, the patterns are hard to tease out, particularly since I’m unsure what tasks are truly being performed. A much larger set of this data across hundreds (perhaps thousands) of domains might produce some insight but for now it seems a lot like reading tea leaves.
Acceptance and Training
The quality rating program has been described in many ways so I’ve always been hesitant to label it one thing or another. Is it a way for Google to see if their recent algorithm changes were effective or is it a way for Google to gather training data to inform algorithm changes?
The answer seems to be yes.
Appen is the company that recruits quality raters. And their pitch makes it pretty clear that they feel their mission is to provide training data for machine learning via human interactions. Essentially, they crowdsource labeled data, which is highly sought after in machine learning.
The question then becomes how much Google relies on and uses this set of data for their machine learning algorithms.
“Reading” The Quality Rating Guidelines

To understand how much Google relies on this data, I think it’s instructive to look at the guidelines again. But for me it’s more about what the guidelines don’t mention than what they do mention.
What query classes and verticals does Google seem to focus on in the rating guidelines and which ones are essentially invisible? Sure, the guidelines can be applied broadly, but one has to think about why there’s a larger focus on … say, recipes and lyrics, right?
Beyond that, do you think Google could rely on ratings that cover a microscopic percentage of total queries? Seriously. Think about that. The query universe is massive! Even the query class universe is huge.
And Google doesn’t seem to be adding resources here. Instead, in 2017 they actually cut resources for raters. Now perhaps that’s changed but … I still can’t see this being a comprehensive way to inform the algorithm.
The raters clearly function as a broad acceptance check on algorithm changes (though I’d guess these qualitative measures wouldn’t outweigh the quantitative measures of success) but also seem to be deployed more tactically when Google needs specific feedback or training data for a problem.
Most recently that was the case with the fake news problem. And at the beginning of the quality rater program I’m guessing they were struggling with … lyrics and recipes.
So if we think back to what Ben Gomes says, the way we should be reading the guidelines is about what areas of focus Google is most interested in tackling algorithmically. As such I’m vastly more interested in what they say about queries with multiple meanings and understanding user intent.
At the end of the day, while the rating guidelines are interesting and provide excellent context, I’m looking elsewhere when analyzing algorithm changes.
Look At The SERP
It surprises a lot how many SEOs rarely directly look at the SERPs, but do that only through “the 👀 “ of a tool. Shame! Look at them & youl’ll:
1) see clearly the search intent detected by Google
2) see how to format your content
3) find On SERPS SEO opportunities pic.twitter.com/Wr4OYAcmiG— Gianluca Fiorelli (@gfiorelli1) October 23, 2018
This Tweet by Gianluca resonated strongly with me. There’s so much to be learned after an algorithm update by actually looking at search results, particularly if you’re tracking traffic by query class. Doing so I came to a simple conclusion.
For the last 18 months or so most algorithm updates have been what I refer to as language understanding updates.
This is part of a larger effort by Google around Natural Language Understanding (NLU), sort of a next generation of Natural Language Processing (NLP). Language understanding updates have a profound impact on what type of content is more relevant for a given query.
For those that hang on John Mueller’s every word, you’ll recognize that many times he’ll say that it’s simply about content being more relevant. He’s right. I just don’t think many are listening. They’re hearing him say that, but they’re not listening to what it means.
Neural Matching
The big news in late September 2018 was around neural matching.
But we’ve now reached the point where neural networks can help us take a major leap forward from understanding words to understanding concepts. Neural embeddings, an approach developed in the field of neural networks, allow us to transform words to fuzzier representations of the underlying concepts, and then match the concepts in the query with the concepts in the document. We call this technique neural matching. This can enable us to address queries like: “why does my TV look strange?” to surface the most relevant results for that question, even if the exact words aren’t contained in the page. (By the way, it turns out the reason is called the soap opera effect).
Danny Sullivan went on to refer to them as super synonyms and a number of blog posts sought to cover this new topic. And while neural matching is interesting, I think the underlying field of neural embeddings is far more important.
Watching search results and analyzing keyword trends you can see how the content Google chooses to surface for certain queries changes over time. Seriously folks, there’s so much value in looking at how the mix of content changes on a SERP.
For instance, the query ‘Toyota Camry Repair’ is part of a query class that has fractured intent. What is it that people are looking for when they search this term? Are they looking for repair manuals? For repair shops? For do-it-yourself content on repairing that specific make and model?
Google doesn’t know. So it’s been cycling through these different intents to see which of them performs the best. You wake up one day and it’s repair manuals. A month of so later they essentially disappear.
Now, obviously this isn’t done manually. It’s not even done in a traditional algorithmic sense. Instead it’s done through neural embeddings and machine learning.
Neural Embeddings
Let me first start out by saying that I found a lot more here than I expected as I did my due diligence. Previously, I had done enough reading and research to get a sense of what was happening to help inform and explain algorithmic changes.
And while I wasn’t wrong, I found I was way behind on just how much had been taking place over the last few years in the realm of Natural Language Understanding.
Oddly, one of the better places to start is at the end. Very recently, Google open-sourced something called BERT.

BERT stands for Bidirectional Encoder Representations from Transformers and is a new technique for pre-NLP training. Yeah, it gets dense quickly. But the following excerpt helped put things into perspective.
Pre-trained representations can either be context-free or contextual, and contextual representations can further be unidirectional or bidirectional. Context-free models such as word2vec or GloVe generate a single word embedding representation for each word in the vocabulary. For example, the word “bank” would have the same context-free representation in “bank account” and “bank of the river.” Contextual models instead generate a representation of each word that is based on the other words in the sentence. For example, in the sentence “I accessed the bank account,” a unidirectional contextual model would represent “bank” based on “I accessed the” but not “account.” However, BERT represents “bank” using both its previous and next context — “I accessed the … account” — starting from the very bottom of a deep neural network, making it deeply bidirectional.
I was pretty well-versed in how word2vec worked but I struggled to understand how intent might be represented. In short, how would Google be able to change the relevant content delivered on ‘Toyota Camry Repair’ algorithmically? The answer is, in some ways, contextual word embedding models.
Vectors
None of this may make sense if you don’t understand vectors. I believe many, unfortunately, run for the hills when the conversation turns to vectors. I’ve always referred to vectors as ways to represent words (or sentences or documents) via numbers and math.
I think these two slides from a 2015 Yoav Goldberg presentation on Demystifying Neural Word Embeddings does a better job of describing this relationship.

So you don’t have to fully understand the verbiage of “sparse, high dimensional” or the math behind cosine distance to grok how vectors work and can reflect similarity.
You shall know a word by the company it keeps.
That’s a famous quote from John Rupert Firth, a prominent linguist and the general idea we’re getting at with vectors.
word2vec
In 2013, Google open-sourced word2vec, which was a real turning point in Natural Language Understanding. I think many in the SEO community saw this initial graph.
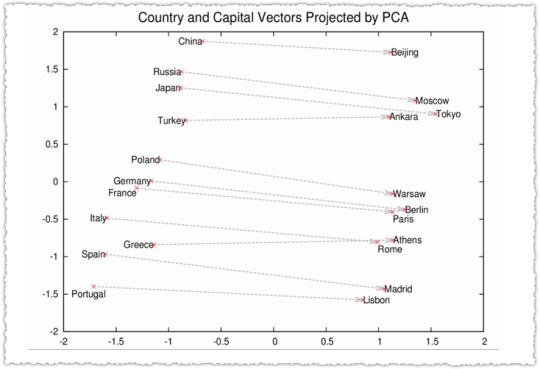
Cool right? In addition there was some awe around vector arithmetic where the model could predict that [King] – [Man] + [Woman] = [Queen]. It was a revelation of sorts that semantic and syntactic structures were preserved.
Or in other words, vector math really reflected natural language!
What I lost track of was how the NLU community began to unpack word2vec to better understand how it worked and how it might be fine tuned. A lot has happened since 2013 and I’d be thunderstruck if much of it hadn’t worked its way into search.
Context
These 2014 slides about Dependency Based Word Embeddings really drives the point home. I think the whole deck is great but I’ll cherry pick to help connect the dots and along the way try to explain some terminology.
The example used is looking at how you might represent the word ‘discovers’. Using a bag of words (BoW) context with a window of 2 you only capture the two words before and after the target word. The window is the number of words around the target that will be used to represent the embedding.

So here, telescope would not be part of the representation. But you don’t have to use a simple BoW context. What if you used another method to create the context or relationship between words. Instead of simple words-before and words-after what if you used syntactic dependency – a type of representation of grammar.
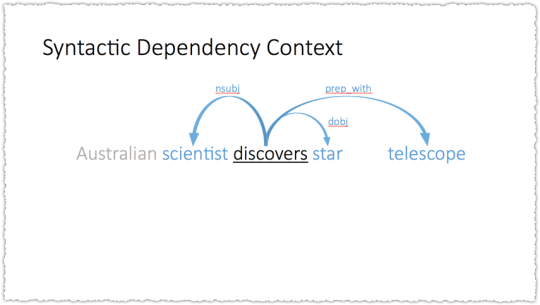
Suddenly telescope is part of the embedding. So you could use either method and you’d get very different results.

Syntactic dependency embeddings induce functional similarity. BoW embeddings induce topical similarity. While this specific case is interesting the bigger epiphany is that embeddings can change based on how they are generated.
Google’s understanding of the meaning of words can change.
Context is one way, the size of the window is another, the type of text you use to train it or the amount of text it’s using are all ways that might influence the embeddings. And I’m certain there are other ways that I’m not mentioning here.
Beyond Words
Words are building blocks for sentences. Sentences building blocks for paragraphs. Paragraphs building blocks for documents.
Sentence vectors are a hot topic as you can see from Skip Thought Vectors in 2015 to An Efficient Framework for Learning Sentence Representations, Universal Sentence Encoder and Learning Semantic Textual Similarity from Conversations in 2018.
Google (Tomas Mikolov in particular before he headed over to Facebook) has also done research in paragraph vectors. As you might expect, paragraph vectors are in many ways a combination of word vectors.
In our Paragraph Vector framework (see Figure 2), every paragraph is mapped to a unique vector, represented by a column in matrix D and every word is also mapped to a unique vector, represented by a column in matrix W. The paragraph vector and word vectors are averaged or concatenated to predict the next word in a context. In the experiments, we use concatenation as the method to combine the vectors.
The paragraph token can be thought of as another word. It acts as a memory that remembers what is missing from the current context – or the topic of the paragraph. For this reason, we often call this model the Distributed Memory Model of Paragraph Vectors (PV-DM).
The knowledge that you can create vectors to represent sentences, paragraphs and documents is important. But it’s more important if you think about the prior example of how those embeddings can change. If the word vectors change then the paragraph vectors would change as well.
And that’s not even taking into account the different ways you might create vectors for variable-length text (aka sentences, paragraphs and documents).
Neural embeddings will change relevance no matter what level Google is using to understand documents.
Questions

You might wonder why there’s such a flurry of work on sentences. Thing is, many of those sentences are questions. And the amount of research around question and answering is at an all-time high.
This is, in part, because the data sets around Q&A are robust. In other words, it’s really easy to train and evaluate models. But it’s also clearly because Google sees the future of search in conversational search platforms such as voice and assistant search.
Apart from the research, or the increasing prevalence of featured snippets, just look at the title Ben Gomes holds: vice president of search, assistant and news. Search and assistant are being managed by the same individual.
Understanding Google’s structure and current priorities should help future proof your SEO efforts.
Relevance Matching and Ranking
Obviously you’re wondering if any of this is actually showing up in search. Now, even without finding research that supports this theory, I think the answer is clear given the amount of time since word2vec was released (5 years), the focus on this area of research (Google Brain has an area of focus on NLU) and advances in technology to support and productize this type of work (TensorFlow, Transformer and TPUs).
But there is plenty of research that shows how this work is being integrated into search. Perhaps the easiest is one others have mentioned in relation to Neural Matching.

The highlighted part makes it clear that this model for matching queries and documents moves beyond context-insensitive encodings to rich context-sensitive encodings. (Remember that BERT relies on context-sensitive encodings.)
Think for a moment about how the matching model might change if you swapped the BoW context for the Syntactic Dependency context in the example above.
Frankly, there’s a ton of research around relevance matching that I need to catch up on. But my head is starting to hurt and it’s time to bring this back down from the theoretical to the observable.
Syntax Changes
I became interested in this topic when I saw certain patterns emerge during algorithm changes. A client might see a decline in a page type but within that page type some increased while others decreased.
The disparity there alone was enough to make me take a closer look. And when I did I noticed that many of those pages that saw a decline didn’t see a decline in all keywords for that page.
Instead, I found that a page might lose traffic for one query phrase but then gain back part of that traffic on a very similar query phrase. The difference between the two queries was sometimes small but clearly enough that Google’s relevance matching had changed.
Pages suddenly ranked for one type of syntax and not another.
Here’s one of the examples that sparked my interest in August of 2017.
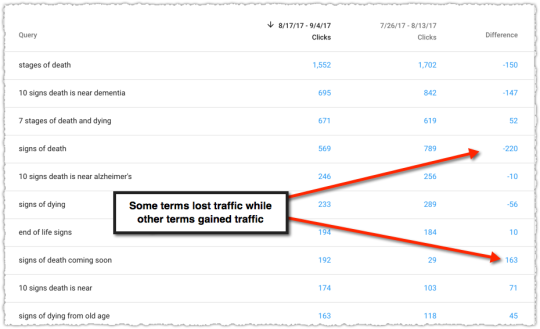
This page saw both losers and winners from a query perspective. We’re not talking small disparities either. They lost a lot on some but saw a large gain in others. I was particularly interested in the queries where they gained traffic.
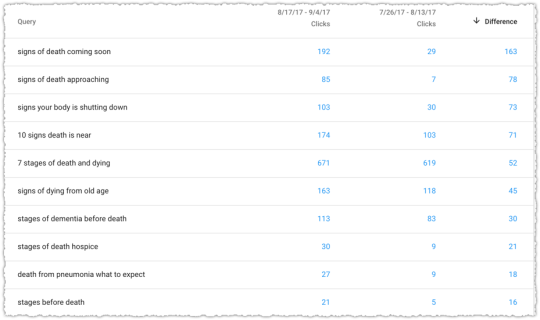
The queries with the biggest percentage gains were with modifiers of ‘coming soon’ and ‘approaching’. I considered those synonyms of sorts and came to the conclusion that this page (document) was now better matching for these types of queries. Even the gains in terms with the word ‘before’ might match those other modifiers from a loose syntactic perspective.
Did Google change the context of their embeddings? Or change the window? I’m not sure but it’s clear that the page is still relevant to a constellation of topical queries but that some are more relevant and some less based on Google’s understanding of language.
Most recent algorithm updates seem to be changes in the embeddings used to inform the relevance matching algorithms.
Language Understanding Updates
If you believe that Google is rolling out language understanding updates then the rate of algorithm changes makes more sense. As I mentioned above there could be numerous ways that Google tweaks the embeddings or the relevance matching algorithm itself.
Not only that but all of this is being done with machine learning. The update is rolled out and then there’s a measurement of success based on time to long click or how quickly a search result satisfies intent. The feedback or reinforcement learning helps Google understand if that update was positive or negative.
One of my recent vague Tweets was about this observation.
Interesting how high volume queries begin to change post-algorithm faster than mid and long-tail queries. The machine learns and can decide faster with more data. #seo
— AJ Kohn (@ajkohn) August 13, 2018
Or the dataset that feeds an embedding pipeline might update and the new training model is then fed into system. This could also be vertical specific as well since Google might utilize a vertical specific embeddings.
August 1 Error
Based on that last statement you might think that I thought the ‘medic update’ was aptly named. But you’d be wrong. I saw nothing in my analysis that led me to believe that this update was utilizing a vertical specific embedding for health.
The first thing I do after an update is look at the SERPs. What changed? What is now ranking that wasn’t before? This is the first way I can start to pick up the ‘scent’ of the change.
There are times when you look at the newly ranked pages and, while you may not like it, you can understand why they’re ranking. That may suck for your client but I try to be objective. But there are times you look and the results just look bad.

The new content ranking didn’t match the intent of the queries.
I had three clients who were impacted by the change and I simply didn’t see how the newly ranked pages would effectively translate into better time to long click metrics. By my way of thinking, something had gone wrong during this language update.
So I wasn’t keen on running around making changes for no good reason. I’m not going to optimize for a misheard lyric. I figured the machine would eventually learn that this language update was sub-optimal.
It took longer than I’d have liked but sure enough on October 5th things reverted back to normal.
August 1 Updates

However, there were two things included in the August 1 update that didn’t revert. The first was the YouTube carousel. I’d call it the Video carousel but it’s overwhelmingly YouTube so lets just call a spade a spade.
Google seems to think that the intent of many queries can be met by video content. To me, this is an over-reach. I think the idea behind this unit is the old “you’ve got chocolate in my peanut butter” philosophy but instead it’s more like chocolate in mustard. When people want video content they … go search on YouTube.
The YouTube carousel is still present but its footprint is diminishing. That said, it’ll suck a lot of clicks away from a SERP.
The other change was far more important and is still relevant today. Google chose to match question queries with documents that matched more precisely. In other words, longer documents receiving questions lost out to shorter documents that matched that query.
This did not come as a surprise to me since the user experience is abysmal for questions matching long documents. If the answer to your question is in the 8th paragraph of a piece of content you’re going to be really frustrated. Google isn’t going to anchor you to that section of the content. Instead you’ll have to scroll and search for it.
Playing hide and go seek for your answer won’t satisfy intent.
This would certainly show up in engagement and time to long click metrics. However, my guess is that this was a larger refinement where documents that matched well for a query where there were multiple vector matches were scored lower than those where there were fewer matches. Essentially, content that was more focused would score better.
Am I right? I’m not sure. Either way, it’s important to think about how these things might be accomplished algorithmically. More important in this instance is how you optimize based on this knowledge.
Do You Even Optimize?
So what do you do if you begin to embrace this new world of language understanding updates? How can you, as an SEO, react to these changes?
Traffic and Syntax Analysis
The first thing you can do is analyze updates more rationally. Time is a precious resource so spend it looking at the syntax of terms that gained and lost traffic.
Unfortunately, many of the changes happen on queries with multiple words. This would make sense since understanding and matching those long-tail queries would change more based on the understanding of language. Because of this, many of the updates result in material ‘hidden’ traffic changes.
All those queries that Google hides because they’re personally identifiable are ripe for change.
That’s why I spent so much time investigating hidden traffic. With that metric, I could better see when a site or page had taken a hit on long-tail queries. Sometimes you could make predictions on what type of long-tail queries were lost based on the losses seen in visible queries. Other times, not so much.
Either way, you should be looking at the SERPs, tracking changes to keyword syntax, checking on hidden traffic and doing so through the lens of query classes if at all possible.
Content Optimization
This post is quite long and Justin Briggs has already done a great job of describing how to do this type of optimization in his On-page SEO for NLP post. How you write is really, really important.
My philosophy of SEO has always been to make it as easy as possible for Google to understand content. A lot of that is technical but it’s also about how content is written, formatted and structured. Sloppy writing will lead to sloppy embedding matches.
Look at how your content is written and tighten it up. Make it easier for Google (and your users) to understand.
Intent Optimization
Generally you can look at a SERP and begin to classify each result in terms of what intent it might meet or what type of content is being presented. Sometimes it’s as easy as informational versus commercial. Other times there are different types of informational content.
Certain query modifiers may match a specific intent. In its simplest form, a query with ‘best’ likely requires a list format with multiple options. But it could also be the knowledge that the mix of content on a SERP changed, which would point to changes in what intent Google felt was more relevant for that query.
If you follow the arc of this story, that type of change is possible if something like BERT is used with context sensitive embeddings that are receiving reinforcement learning from SERPs.
I’d also look to see if you’re aggregating intent. Satisfy active and passive intent and you’re more likely to win. At the end of the day it’s as simple as ‘target the keyword, optimize the intent’. Easier said than done I know. But that’s why some rank well and others don’t.
This is also the time to use the rater guidelines (see I’m not saying you write them off completely) to make sure you’re meeting the expectations of what ‘good content’ looks like. If your main content is buried under a whole bunch of cruft you might have a problem.
Much of what I see in the rater guidelines is about capturing attention as quickly as possible and, once captured, optimizing that attention. You want to mirror what the user searched for so they instantly know they got to the right place. Then you have to convince them that it’s the ‘right’ answer to their query.
Engagement Optimization
How do you know if you’re optimizing intent? That’s really the $25,000 question. It’s not enough to think you’re satisfying intent. You need some way to measure that.
Conversion rate can be one proxy? So too can bounce rate to some degree. But there are plenty of one page sessions that satisfy intent. The bounce rate on a site like StackOverflow is super high. But that’s because of the nature of the queries and the exactness of the content. I still think measuring adjusted bounce rate over a long period of time can be an interesting data point.
I’m far more interested in user interactions. Did they scroll? Did they get to the bottom of the page? Did they interact with something on the page? These can all be tracking in Google Analytics as events and the total number of interactions can then be measured over time.
I like this in theory but it’s much harder to do in practice. First, each site is going to have different types of interactions so it’s never an out of the box type of solution. Second, sometimes having more interactions is a sign of bad user experience. Mind you, if interactions are up and so too is conversion then you’re probably okay.
Yet, not everyone has a clean conversion mechanism to validate interaction changes. So it comes down to interpretation. I personally love this part of the job since it’s about getting to know the user and defining a mental model. But very few organizations embrace data that can’t be validated with a p-score.
Those who are willing to optimize engagement will inherit the SERP.
There are just too many examples where engagement is clearly a factor in ranking. Whether it be a site ranking for a competitive query with just 14 words or a root term where low engagement has produced a SERP geared for a highly engaging modifier term instead.
Those bound by fears around ‘thin content’ as it relates to word count are missing out, particularly when it comes to Q&A.
TL;DR
Recent Google algorithm updates are changes to their understanding of language. Instead of focusing on E-A-T, which are not algorithmic factors, I urge you to look at the SERPs and analyze your traffic including the syntax of the queries.
The Next Post: What I Learned In 2018
The Previous Post: Tracking Hidden Long-Tail Search Traffic
[ad_2]
Source link



